
Large Language Models (LLMs) have revolutionized artificial intelligence, enabling powerful applications in natural language processing (NLP), from chatbots to advanced content generation. Creating an LLM from scratch is a highly technical process, requiring deep expertise in AI, access to robust infrastructure, and substantial resources. In this comprehensive guide, we’ll explore the entire journey, from conceptualization to deployment.
Understanding the basics
1. What is a Large Language Model?
A Large Language Model is an AI system trained to understand and generate human-like text. These models are based on deep learning architectures like transformers, which excel at identifying patterns in language data and predicting textual outputs.

Key Characteristics of LLMs
Scale:
Trained on billions of tokens (textual units) with billions or even trillions of parameters.
Large scale in Large Language Models (LLMs) refers to the deliberate and systematic increase in model size, training data, and computational resources, enabling these models to achieve unprecedented levels of performance and versatility. At its core, scaling involves expanding the number of parameters in a model—ranging from millions in early models to hundreds of billions or even trillions in cutting-edge ones like GPT-4 and PaLM. This expansion allows models to capture intricate patterns in data, making them capable of understanding complex language structures, performing sophisticated reasoning, and even generating contextually relevant content with remarkable coherence. Scaling also extends to the training datasets, which encompass massive and diverse collections of text drawn from books, websites, academic papers, and other sources. By training on datasets containing trillions of tokens, LLMs become proficient in a wide range of topics and domains, reducing bias and improving generalization. Additionally, scaling requires significant computational resources, leveraging powerful hardware like GPUs and TPUs along with distributed computing techniques such as model parallelism and data parallelism.
These advancements in computation make it feasible to train and deploy massive models while ensuring efficiency. As models scale, they often exhibit emergent capabilities—complex behaviors and skills that arise without explicit programming, such as performing zero-shot and few-shot tasks, generating creative content, and reasoning logically across domains. However, scaling also comes with challenges, including high computational costs, energy consumption, and the risk of diminishing returns, where performance improvements taper off despite increasing resources. Despite these challenges, scaling remains a cornerstone of progress in LLM research, driving innovations in natural language processing, conversational AI, and a host of real-world applications.
Versatility:
Capable of diverse tasks like translation, summarization, and creative writing.
Versatility in Large Language Models (LLMs) refers to their remarkable ability to perform a wide range of tasks across diverse domains with minimal customization or additional training, making them highly adaptable and multifunctional. This versatility is primarily driven by the extensive scale and diversity of their training data, which typically includes text from numerous sources such as books, scientific articles, websites, and code repositories.As a result, LLMs develop a broad understanding of language and knowledge, enabling them to perform tasks ranging from content creation, translation, summarization, and question answering to more specialized applications like generating code, debugging software, and even assisting in scientific research. Unlike traditional models that require task-specific training, LLMs can often generalize to new tasks with simple instructions or examples, a capability known as few-shot or zero-shot learning.
Their contextual understanding allows them to process and generate coherent text based on nuanced prompts, making them effective in conversational AI, customer service, education, and creative industries. Furthermore, LLMs demonstrate emergent properties, such as reasoning, logic, and the ability to handle ambiguous or incomplete input, enhancing their adaptability to complex and open-ended tasks. This versatility also extends to multimodal systems, where LLMs integrated with vision models can analyze and generate text related to images or other media, broadening their utility.
Pre-training and Fine-tuning:
General language understanding is achieved via pre-training on massive datasets, while fine-tuning adapts the model for specific tasks.
Pre-training and fine-tuning are the two core phases in developing Large Language Models (LLMs), each playing a crucial role in their functionality. Pre-training is the initial stage where the model is exposed to massive and diverse text data to learn general linguistic patterns, grammar, semantics, and context. This process is unsupervised, relying on objectives like predicting missing words (masked language modeling) or the next word in a sequence (causal language modeling). It equips the model with broad, transferable knowledge, forming a foundation for various language tasks. However, while pre-training makes the model proficient in general language understanding, it is not specialized for specific applications.
This is where fine-tuning comes in. In this second phase, the pre-trained model is trained further on smaller, task-specific datasets, often using supervised learning. Fine-tuning tailors the model to excel in specific tasks like sentiment analysis, translation, or summarization by aligning its general knowledge with particular objectives. Together, pre-training provides generality, while fine-tuning adds specificity, making LLMs highly adaptable and effective across a wide range of applications.
2.Prerequisites for Building an LLM
Skills and Expertise
- Programming Proficiency: Strong command of Python and libraries like PyTorch or TensorFlow.
- Machine Learning Foundations: Knowledge of deep learning techniques, optimization algorithms, and regularization.
- Natural Language Processing (NLP): Understanding tokenization, embeddings, attention mechanisms, and evaluation metrics.
Infrastructure Requirements
Storage: Significant disk space for datasets, checkpoints, and logs.
High-Performance Computing (HPC): Access to GPUs or TPUs, ideally with distributed training capabilities.
Cloud Platforms: AWS, Google Cloud, Azure, or specialized AI platforms like Paperspace.
3.Step-by-Step Guide to Building an LLM
Step 1: Define Objectives
Establish a clear purpose for the model:
- General-purpose conversational AI?
- Specialized industry application (e.g., healthcare, legal)?
Define the desired scale, balancing capability and computational constraints.
Step 2: Data Collection and Preprocessing
- Gather Data:
- Use publicly available datasets (e.g., Common Crawl, Wikipedia, OpenWebText).
- Augment with domain-specific datasets if needed.
- Ensure data diversity to improve generalization.
- Preprocess the Data:
- Remove duplicates, irrelevant data, and special characters.
- Tokenize the text into manageable units (words, subwords, or characters).
- Normalize the text (lowercasing, removing unnecessary spaces, etc.).
- Tools for Preprocessing:
- Use libraries like NLTK, SpaCy, or custom scripts for cleaning.
- Employ tokenization tools such as Hugging Face’s Tokenizer library or Google’s SentencePiece.
Step 3: Design the Model Architecture
The transformer architecture underpins most modern LLMs. Key components include:
- Embedding Layer: Converts tokens into dense vector representations.
- Multi-Head Self-Attention: Allows the model to focus on different parts of the input sequence.
- Feed-Forward Layers: Process information post-attention for feature extraction.
- Layer Normalization and Residual Connections: Ensure stable training and reduce vanishing gradients.
- Output Layer: Predicts the next token or the missing word in the sequence.
Use frameworks like PyTorch, TensorFlow, or JAX to implement the architecture.
Step 4: Pre-training the Model
- Objective: Train the model to predict the next token in a sequence (causal language modeling) or fill in blanks (masked language modeling).
- Loss Function: Use cross-entropy loss for classification tasks.
- Optimization: Employ advanced optimizers like AdamW with learning rate schedulers.
- Compute Strategy:
- Implement distributed training across multiple GPUs or TPUs.
- Use frameworks like NVIDIA’s Apex or PyTorch’s distributed library.
Step 5: Fine-tuning for Specific Tasks
Fine-tuning adapts the general-purpose LLM to specific tasks or domains.
- Use task-specific datasets (e.g., legal documents for legal AI).
- Adjust hyperparameters like learning rate and batch size for the task.
Step 6: Model Evaluation
Evaluate the model using quantitative and qualitative methods:
- Perplexity: Measures how well the model predicts sequences.
- BLEU/ROUGE Scores: Evaluate generated text against references.
- Human Feedback: Gather insights on the model’s coherence and relevance.
Step 7: Model Optimization
To make the LLM practical for deployment:
- Quantization: Reduce model size by representing weights with fewer bits.
- Distillation: Train a smaller, faster model (student) using the larger model (teacher) as a guide.
- Pruning: Remove less significant parts of the model to save resources.
Step 8: Deployment
- Frameworks: Use TensorFlow Serving, ONNX, or FastAPI to create scalable APIs.
- Infrastructure: Deploy on cloud services or edge devices, depending on latency requirements.
- Monitoring: Continuously monitor model performance and update as needed.
4.Challenges in Building LLMs
Computational and Resource Demands
Building LLMs requires vast computational power, with training often involving exaflops of computing and massive hardware infrastructures like GPUs or TPUs. The training process itself can take weeks or months, depending on the model size. This makes the development of state-of-the-art LLMs extremely expensive, limiting access to only well-funded organizations or research institutions. The cost of scaling models also raises concerns about sustainability, as the environmental impact of running these large-scale systems can be significant due to the energy consumption involved.

Data Quality and Bias
LLMs are highly dependent on the data used for training, and this presents challenges in terms of both data quality and data bias. Since LLMs are trained on vast, uncurated datasets scraped from the internet, they often learn undesirable patterns from biased, harmful, or incomplete data. This can lead to the model reproducing stereotypes, prejudices, and misinformation, which poses serious ethical concerns, particularly when models are deployed in real-world applications where fairness and accuracy are critical. Ensuring that data is both diverse and representative, while minimizing harmful biases, remains an ongoing challenge in the development of ethical LLMs.

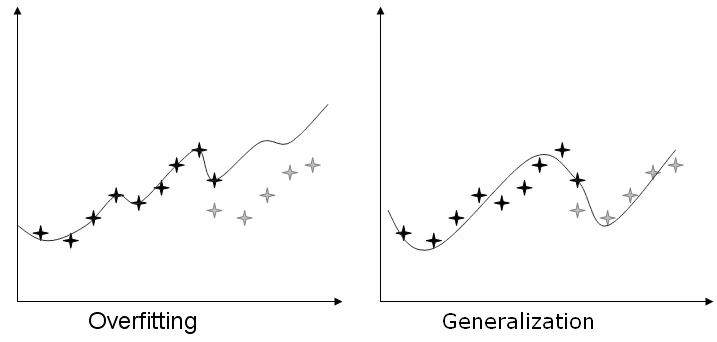
Overfitting and Generalization
While LLMs are designed to generalize from large datasets, there is always the risk of overfitting—when the model learns patterns that are too specific to the training data and fails to perform well on new, unseen data. Striking the right balance between generalization and specialization is tricky, especially as models scale. Overfitting can occur if a model is fine-tuned too heavily on a small dataset or if the data is not representative of the target domain. Addressing these issues requires careful training and evaluation techniques to ensure that the model can adapt to new tasks without sacrificing performance.
Ethical and Safety Concerns
As LLMs become more powerful and pervasive, their ethical and safety implications become more pronounced. A key concern is the potential for misuse, as LLMs can generate misleading information, harmful content, or malicious code. Ensuring that LLMs behave in ways that align with societal values, mitigate harm, and avoid unethical outputs (e.g., deepfakes, hate speech, or disinformation) is a major challenge. Furthermore, aligning the model with user intentions—ensuring it answers questions accurately, provides unbiased recommendations, and avoids generating inappropriate responses—is complex and ongoing work.

Interpretability and Transparency
LLMs, particularly those with billions of parameters, are often considered “black boxes.” Understanding why a model makes certain decisions or generates specific outputs is challenging, making it difficult to debug, trust, or improve the models. This lack of interpretability raises issues, particularly in high-stakes applications like healthcare, law, and finance, where transparency and accountability are essential. Developing methods for explainable AI that can provide insights into the decision-making processes of LLMs is an ongoing challenge.

Scalability and Efficiency
As models scale up in terms of parameters, the complexity of managing and deploying these systems increases. Efficient scaling becomes a challenge when balancing the benefits of larger models with the need for computational efficiency. Optimizing the trade-off between performance, speed, and resource consumption is essential to making LLMs practical for real-time applications and wide-scale deployment. Techniques like model compression, quantization, and pruning aim to reduce the size and complexity of these models without sacrificing accuracy, but these methods still face technical limitations.

Societal and Regulatory Impacts
As LLMs gain more influence in applications like content generation, healthcare, customer support, and education, there are growing concerns about their societal impact. The potential for job displacement, manipulation through automated content generation, and the risk of reinforcing harmful ideologies or misinformation is real. This raises questions about how LLMs should be regulated and monitored. Regulatory frameworks that ensure responsible use, prevent harm, and promote accountability are needed, but such frameworks are still in early development. Moreover, issues related to data privacy and intellectual property further complicate the deployment of LLMs in different regions and industries.
5.Tools and Resources
Frameworks and Libraries
- Hugging Face Transformers: Simplifies working with transformers.
- PyTorch/TensorFlow: Popular frameworks for deep learning.
- Tokenization Libraries: SentencePiece, BERT Tokenizer.
Datasets
- Common Crawl: Massive web-scraped dataset.
- Wikipedia Dumps: Clean and structured text.
- Hugging Face Datasets: Preprocessed datasets for various tasks.
Research Papers
- Attention is All You Need (Vaswani et al., 2017): Introduced the Transformer.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018).
- GPT-3: Language Models are Few-Shot Learners (Brown et al., 2020).
6. Costs of Building an LLM
Building an LLM involves expenses related to:
- Hardware: High-end GPUs/TPUs.
- Storage: Petabytes of storage for data.
- Development: Salaries for a team of AI experts.
For smaller-scale models, leveraging open-source frameworks and cloud compute services can significantly reduce costs.